
Dans le post précédent, nous avons décrit les sept rôles à couvrir dans une équipe produit data : Business Developer, Product Owner, Product Designer, Developer (front/back), Data Engineer, Data Scientist, Product Manager. On confond souvent ces rôles avec les emplois associés ; certaines organisations produit recrutent des Data Scientist et des Business Developer, mais d’autres pas. Parfois le rôle de Business Developer est occupé par un commercial ou un chargé de marketing. De même les rôle de Product Owner, Product Manager, Product Designer peuvent parfois être occupés par une seule et même personne. Pour autant, occuper chacun de ces rôles nécessite des compétence bien précises, et tout le monde ne peut pas tout faire.
En analysant plusieurs centaines de profils LinkedIn, nous avons dégagé 12 grandes catégories de compétences que nous décrivons dans cet article :
Customer Relation
Initier, maintenir et faire fructifier une relation durable avec les clients potentiels.
Comme décrit précédemment (§ 1.2.1), la démarche commerciale ne consiste plus seulement à proposer le bon produit et à en faire percevoir les mérites, mais d’entretenir des conversations sur les sujets qui intéressent le client, au cours desquelles le produit pourra être proposé au moment opportun.
« Dans un monde de surabondance, l’entreprise doit construire des conversations avec ses clients et développer une intimité qui légitime la pertinence des solutions qu’elle propose. »
Caseau Y. (2020) L’Approche lean pour la transformation digitale, Dunod, p. 7
De manière complémentaire au Customer Knowledge, la relation client consiste donc à développer une intimité bilatérale avec le client ou les communautés de clients. Elle demande de savoir poser les bonnes questions, d’écouter avec attention, et elle se nourrit bien sûr d’une bonne compréhension du client.
On ne dit pas qu’on a un truc qui marche, on fait parler d’abord puis on propose. « Si vous dites qu’on arrive avec un outil […], le client va vous jeter. »
Il faut montrer qu’on s’occupe de lui.
Customer Knowledge
Collecter, capitaliser et interpréter les informations permettant de mieux comprendre le client.
Ces informations peuvent provenir de différentes sources : rencontres physiques, échanges téléphoniques, trace laissée sur un site web, dans une application, sur les réseaux sociaux. Ces compétences nécessitent une grande maîtrise technique pour tirer parti des interactions digitales, mais également un « sens de l’humain » particulièrement développé pour comprendre les véritables motivations de chaque groupe de client.
Pour découvrir les besoins clients, il faut des ethnologues, des anthropologues ; « c’est un métier d’arriver à comprendre ce qu’il y a dans la tête des gens. […] Faire émerger les aspirations profondes des gens, des entreprises, c’est un talent. »
« C’est presque le psy de l’utilisateur » ; il faut savoir « accoucher le client de son problème ».
La connaissance client est souvent perçue comme une activité technique consistant à décortiquer les données collectées sur les réseaux sociaux ; on voit que cette compétence se rapproche plus de l’anthropologie. Certaines entreprises n’hésitent d’ailleurs pas à embaucher des anthropologues d’entreprise, dont l’activité est d’observer les comportements des utilisateurs pour faire émerger de nouvelles connaissances sur leurs besoins. D’autres confient ce rôle au Product Designer en parlant de recherche utilisateur (User research)
Agile Project Management
Planifier, organiser et animer le travail d’équipe pour la réalisation du produit. Comme nous l’avons vu précédemment (§ 1.1.6), l’objectif est d’avoir des retour clients fréquents et des boucles de validation des enseignements les plus rapides possible. Cela nécessite d’organiser le travail d’une manière particulière, compatible avec d’éventuels changements de spécification en cours de route. Différentes méthodes agiles ont été développées dans ce but : Scrum, Xtreme Programming…
« Aujourd’hui, le manifeste agile, la culture produit et le mouvement Lean Startup […] poussent entre autres à s’adapter en permanence au contexte et aux besoins, à tester le plus vite possible les hypothèses sur le terrain et à avancer en apprenant de ces expérimentations… Concrètement, vous devrez toujours confronter votre travail aux retours des utilisateurs, et ce, le plus rapidement et fréquemment possible. L’une des 4 valeurs présentées dans le manifeste agile est d’ailleurs “L’adaptation au changement plus que le suivi d’un plan”. »
Thiga (2019) Product Academy vol. 2 : Growth, p. 88-89
La compétence de Agile Project Management est donc spécifique à la maîtrise et la pratique de ces méthodes et demande un apprentissage, même lorsque l’on est familier avec la gestion de projet « classique ».
Elle nécessite par ailleurs de savoir communiquer et favoriser la communication au sein de l’équipe, de savoir animer et faire respecter la méthodologie. Et elle nécessite enfin une bonne capacité à prendre du recul pour ajuster les outils au contexte et respecter la complémentarité des rôles au sein de l’équipe.
Design Thinking
Concevoir une expérience utilisateur (UX) de manière itérative.
Comme décrit dans le précédent post, l’expérience est ce que vit l’utilisateur au contact du produit. Il est nécessaire de concevoir cette expérience en parallèle du produit et de la compréhension de l’utilisateur. Par exemple, si le produit était une voiture, l’expérience serait le voyage en voiture : s’il s’avère que le voyage est un trajet intercontinental, le produit « voiture » doit être reconsidéré. Comme une expérience est un parcours à plusieurs étapes, il faut être capable de construire une version initiale du parcours, de le prototyper à faible coût, de le tester auprès du client, et d’améliorer les étapes imparfaites.
« Design Thinking : Application d’un processus itératif et d’une approche visant à comprendre les utilisateurs, remettre en question les hypothèses et redéfinir les problèmes, afin de générer des solutions innovantes répondant aux besoins réels des utilisateurs. »
Très liée avec le Customer Knowledge, cette compétence nécessite avant tout des capacités relationnelles : savoir écouter, poser les bonnes questions, animer un brainstorming créatif et efficace. Elle requiert également une bonne maîtrise méthodologique pour jongler avec les 5 étapes de la démarche (comprendre le client, définir le problème, penser une solution, prototyper, tester). Et elle nécessite enfin un savoir-faire technique – en particulier sur la phase de prototypage et de test, pour construire des maquettes de qualité, définir les moyens de tester les hypothèses et bien interpréter les résultats.
UI Design
Concevoir l’interface utilisateur du produit, c’est-à-dire les moyens par lesquels le client pourra interagir avec le produit.
Pour reprendre la métaphore de la voiture, il s’agit du volant, des pédales, du levier de vitesse, les poignées de portes, les boutons dans l’habitacle qui permettent d’agir sur le produit ; mais il s’agit également de tout ce qui permet de recevoir des informations de la part du produit : pare-brise, tableau de bord, voyants lumineux, signaux sonores…
« Cette discipline correspond à l’art de concevoir la couche graphique d’un produit digital. Le Product Designer traduit l’identité de marque et donne du sens en structurant les écrans et les composants graphiques dans un ensemble cohérent et esthétique. »
Thiga (2020) Product Academy vol. 4 : Le Product design dans une
organisation produit, p. 21
L’enjeu est en effet double : il faut que le résultat soit attrayant ; ce qui nécessite de bonnes compétences artistiques et des outils associés (Adobe Illustrator et Photoshop sont les plus connus). Mais il faut également que le résultat permette une interaction naturelle, simple, évidente avec le produit.
« Une interface utilisateur, c’est comme une blague.
@MartinLeBlanc (2014), Twitter https://bit.ly/2FJ0VDr
Si vous devez l’expliquer, c’est qu’elle n’est pas si bonne. »
Ainsi, le designer doit avoir une bonne compréhension de la logique inconsciente de l’utilisateur ; recoupant ainsi les compétences de Design thinking et de Customer Knowledge.
Enfin, le design doit produire une interface réalisable techniquement, ce qui nécessite souvent de connaitre voire de maîtriser les technologies de rendu web ou mobile.
Programming
Concevoir, produire et perfectionner du code informatique, pour produire la couche logicielle du produit.
En fonction des rôles qu’occupe un programmeur, il devra maitriser un jeu de technologies différentes : Le développeurs front doivent être familiers avec les technologies de développement web (HTML, CSS, Angular, …), les développeurs back utiliseront d’autres outils (Java, Go, Ruby, Python…). Mais certains outils devront être connus de tous : pour la gestion de version du code (Git, Svn), pour la création d’API (OpenAPI), pour documenter le code (Sphinx, Doxygen…).
Comme pour l’Analytics, le développement nécessite de savoir accéder à la donnée dans les bases, la manipuler, la transformer.
« Être capable de manipuler des fichiers texte en ligne de commande, comprendre les opérations vectorialisées, penser de manière algorithmique ; ce sont les hacking skills qui constituent un data hacker accompli. »
Conway D. (2013) The Data Science Venn Diagram
Enfin, le développement agile demande de reprendre régulièrement le code qui a été écrit par le passé afin de le simplifier et de le consolider. En effet, comme la conception du logiciel se fait au gré de l’expression des besoins, il est souvent nécessaire de reprendre le code pour lui donner a posteriori une cohérence. Faute d’effectuer cette activité de refactoring, on accumule une « dette technique » correspondant à l’effort qu’il faudra produire pour rendre viables les fonctionnalités déjà présentées au client. La capacité à effectuer ce refactoring au fur et à mesure est souvent nommée craftsmanship car elle demande une attention permanente, du soin et un goût prononcé pour le travail de qualité.
« Les craftsmen sont adeptes de la Boy Scout Rule appliquée au code “Leave code in a better state” (Robet C. Martin). Elle permettra à votre équipe de s’attaquer à la dette technique quasi gratuitement. Le principe est simple : à chaque fois que quelqu’un touche un bout de code, il devra le laisser dans un état meilleur. Une simple question d’amélioration continue ! »
Thiga (2019) Product Academy vol. 1: Agile Product Management, p. 52.
Operations
Gérer l’administration et le fonctionnement du système informatique.
Derrière les services logiciels se cache une infrastructure informatique, avec ses contraintes, ses limitations, ses problèmes. Il s’agit de savoir mettre en œuvre l’exécution des applications sur les machines en place (integration), de vérifier que les calculs couteux ne se télescopent pas (orchestration), de surveiller le bon fonctionnement de chaque machine et de chaque service (monitoring), de gérer les surprises et les éventuelles crises (recovery).
Cette compétence demande une très bonne connaissance informatique, tant du point de vue logiciel que matériel. Elle nécessite aussi de maîtriser un certain nombre d’outils et de technologies dédiées (intégration continue, gestion de version, containerisation et orchestration, analyse des logs…).
Elle demande enfin de savoir alterner entre une organisation rigoureuse (pour prévenir les problèmes et capitaliser les apprentissages) et une grande souplesse (pour faciliter l’activité et bien gérer les crises).
Architecture
Concevoir et mettre en œuvre l’organisation entre plusieurs systèmes.
Ces systèmes peuvent être des briques technologiques (capteurs, transmetteurs, services logiciels …) – on parle alors d’architecture système ou de System Design. Ce peut être un ensemble de technologies pour héberger et restituer les données – on parle de Datalake Architecture. Il peut encore s’agir d’Architecture data ou datamart, consistant à organiser les données de manière qu’elles soient faciles à exploiter.
Il faut distinguer deux compétences en database : le datalake d’une part – il s’agit du réservoir de données – et le datamart d’autre part, c’est-à-dire la partie opérationnelle sur laquelle on fait tourner les modèles.
Cette compétence nécessite de se tenir au courant des tendances du marché, pour connaitre les technologies utilisées dans le secteur et les problématiques qu’elles cherchent à résoudre. Elle demande aussi une bonne capacité à anticiper pour entrevoir les usages, les opportunités, les problèmes à venir. Mais elle demande avant tout de savoir communiquer simplement des concepts complexes et abstraits. En effet, dans une organisation pratiquant les méthodes agiles, l’enjeu de l’architecte est plus de limiter l’apparition de « dette technique » que de définir des règles à appliquer. Il doit pour cela faire comprendre ses intentions à ses coéquipiers pour que spontanément ils agissent conformément à la vision établie.
« L’équipe doit comprendre à la fois le fonctionnement interne de son produit et surtout l’intégration de ce produit dans le système global. On retrouve ici l’importance du management visuel qui est l’héritage du lean manufacturing dans la tradition du Toyota Way. L’équipe doit développer une compréhension fine du fonctionnement des systèmes, et surtout visualiser cette compréhension sur des visuels affichés aux murs afin qu’ils deviennent une compréhension partagée. »
Caseau Y. (2020) L’Approche lean pour la transformation digitale, Dunod, p. 147-148.
Machine Learning
Concevoir, programmer, ajuster et valider des modèles mathématiques.
Comme son nom l’indique, cette compétence aspire à transférer aux ordinateurs des connaissances leur permettant d’effectuer automatiquement certaines tâches : classer, prédire, recommander, décider…
Après une phase de conception où l’on élabore les hypothèses du modèle, celui-ci est programmé sur la machine, puis ajusté à partir des données : c’est-à-dire que l’on demande à la machine de trouver elle-même la valeur de certains paramètres pour que le modèle corresponde aux données observées. Par exemple sur la Figure ci-dessous, l’ingénieur a choisi la forme du modèle (linéaire par morceaux – plusieurs segments de droite) et c’est la machine qui a trouvé le positionnement des points qui permet à la courbe de s’ajuster au mieux aux observations.

Figure 17 : Exemple d’ajustement d’un modèle linéaire par morceaux
On remarque que l’ingénieur aurait pu choisir d’autres modélisations pertinentes : morceau de cercle, d’ellipse, de parabole… Ce choix est un compromis entre plusieurs facteurs : simplicité du modèle, rapidité d’exécution, précision, facilité d’ajustement, robustesse…
La compétence Machine Learning demande donc de connaitre et de maitriser une variété de modèles, de connaitre leurs avantages et inconvénients, d’avoir un regard critique sur l’intérêt de chacun.
Elle nécessite aussi une prise de recul sur la démarche et de la rigueur méthodologique. Il est fréquent en effet de voir de jeunes data scientist utiliser (sans succès) une méthode de clustering pour résoudre un problème de régression (cf. Figure ci-dessous) ; soit parce qu’ils maitrisent mieux les méthodes de clustering, soit parce qu’ils n’ont pas collecté les données qui leur permettraient de construire une prédiction.

Enfin, le Machine Learning demande une bonne compréhension de la théorie des probabilités – de la théorie de l’information en particulier – pour être capable de déterminer rapidement le potentiel d’un jeu de données : si on ne dispose pas de la bonne donnée, il vaut mieux le savoir tout de suite plutôt qu’essayer d’entraîner une machine à « inventer » de l’information.
Analytics
Collecter, traiter et analyser les données de manière à permettre une prise de décision éclairée par les données (data-informed) voire pilotée par les données (data-driven).
On a vu en effet dans l’article précédent que la donnée est à la fois la source et le résultat de la démarche produit. Il faut donc être capable d’en extraire le sens, pour fermer la boucle de validation des enseignements.
En 2013, Drew Conway a posé une définition désormais consensuelle de la compétence data science (cf. Figure ci-dessous) : il s’agit de la combinaison de capacités à manipuler la donnée sur ordinateur (Hacking Skills), de connaissances en mathématiques et statistiques, et d’une réelle expertise dans le domaine d’activité concerné.
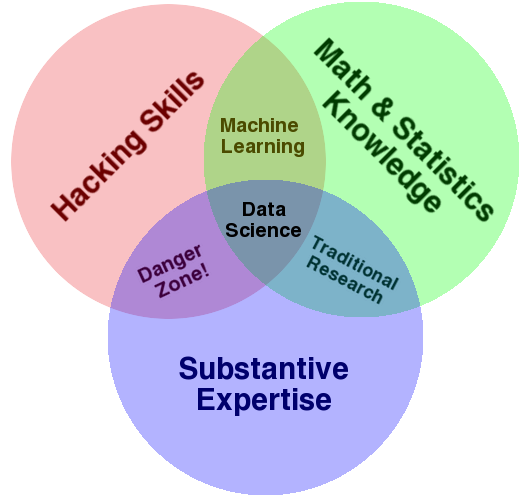
Conway D. (2013) The Data Science Venn Diagram
Il explique en effet que la valeur ajoutée du Data Scientist est de poser les questions pertinentes, autant que de savoir les résoudre.
« La science consiste à découvrir et construire des connaissances, ce qui nécessite des questions motivantes sur le monde et des hypothèses qui peuvent être confrontées aux données et testée par des méthodes statistiques. »
Conway D. (2013) The Data Science Venn Diagram
La compétence Analytics est la branche de la data science qui est tournée vers l’expertise métier. Elle nécessite la connaissance des principaux outils de manipulation de données : Excel, Access, Tableau, PowerPivot, Google Analytics… Elle nécessite aussi une bonne maîtrise des théories statistiques : tests d’hypothèses, probabilités, méthodes de sondage… En effet, comme le souligne l’étiquette « Danger Zone ! » dans le diagramme de Conway, le défaut de rigueur statistique dans l’interprétation des données peut conduire à des erreurs lourdes (échantillon biaisé, résultat non significatif, cum-ergo [1]…).
Parmi les data-scientists, « il faut se méfier comme de la peste de ceux qui n’ont pas de notion de théorie des sondages. »
Mais surtout, l’Analytics nécessite une très bonne compréhension de l’activité et de son contexte, pour établir le lien entre les données et la réalité, pour construire une « stratégie analytique » : formuler les bonnes hypothèses, choisir les métriques appropriées, en déduire des enseignements valides.
Enfin, l’Analytics demande de savoir représenter l’information de la meilleure manière (on parle de data-viz ou de visual analytics). En phase exploratoire, il est en effet critique de représenter l’information de la bonne manière, en fonction de la nature des données et de l’enseignement que l’on espère en tirer.
[1] Cum ergo : Du latin « Cum ergo hoc propter ergo » ; erreur consistant à interpréter (à tort) une corrélation statistique comme étant la preuve d’une causalité. Par exemple, des producteurs de jouets changent leur packaging en novembre et leurs ventes augmentent en décembre. Est-ce le changement de packaging qui a provoqué l’augmentation, ou les fêtes de fin d’année ? Peut-être que les fêtes de fin d’année sont même la cause du changement de packaging… ?
Data Strategy
Etablir une stratégie d’entreprise prenant en compte les aspects liés aux données, aux moyens de les obtenir et de les valoriser.
Parmi les ressources d’une entreprise, les données ont une valeur toute particulière. Profondément immatérielles, elles sont faciles à partager et peuvent radicalement changer les rapports de force entre acteurs économiques. C’est comme si une bataille du XIX° siècle se jouait tout à coup avec la possibilité de téléporter les régiments : le fond du canevas stratégique est transformé.
La Data Strategy consiste à prendre en compte les particularités des données pour exploiter les nouvelles possibilités stratégiques, et maximiser la valeur tirée des données de l’entreprise (ou de sa capacité à en obtenir). Elle s’appuie sur une excellente compréhension des acteurs économiques ; que ce soit dans le domaine d’activité de l’entreprise ou au dehors. Et elle consiste également à avoir une bonne maîtrise des ressources digiales de l’entreprise à travers une organisation rigoureuse : la data gouvernance.
En effet, la manipulation des données présente des risques de différentes natures : non-respect de la réglementation, fuite de données confidentielles ou secrètes, pertes ou altération de données critiques, cyber-attaque, virus, panne… La plupart de ces risques peuvent avoir un impact majeur : interruption du service, pertes financières, atteinte à l’image de l’entreprise.
« [La data governance] est compliquée à mettre en place parce que ça a un lien avec des processus, des rôles, des responsabilités. Souvent on doit mettre en place de nouveau rôles au sein de l’équipe, ce qu’on appelle des data owners. […] Mais également il y a tout ce qui est conformité réglementaire, avec le RGPD par exemple. Il y a énormément de choses à mettre en place et c’est souvent dans des structures qui ne sont pas habituées de faire de la gouvernance transverse. Donc c’est un gros bloc qui peut prendre beaucoup de temps. »[1]
Hubvisory (2020) Ask me Anything #10 : le Data Product Management, 00:34:40.
Comme pour l’Architecture, l’enjeu est de diffuser dans l’équipe les schémas à respecter, afin d’éviter la création d’une « dette compliance » qui aurait deux effets néfastes : c’est un risque supplémentaire (non maîtrisé) pour l’entreprise, et il amène généralement à introduire de nouvelles contraintes qui pénalisent la démarche d’innovation.
La Data Governance demande donc une bonne connaissance des risques auxquels s’expose l’organisation (notions de droit, de cybersécurité, du sûreté) et des moyens de les mettre sous contrôle (définition de rôles, documentation des responsabilités, gestion des droits, détection des usages inattendus…) ; et elle nécessite aussi de savoir construire et diffuser une vision claire des enjeux de gouvernance et des principes à suivre.
Business Model
Mettre au point et valider les modèles d’affaires ; c’est-à-dire des hypothèses sur le client et sur sa réaction vis-à-vis du produit.
Eric Ries parle de « moteur de croissance » pour expliquer qu’il s’agit dans un premier temps de dessiner les grandes lignes du modèle (construire le moteur), et par la suite de procéder à des tests et ajustements pour optimiser son cycle de fonctionnement. Si certaines hypothèses s’avèrent fausses, il faut savoir changer la logique de fonctionnement du modèle : il parle alors de pivot.
Il existe de multiple « canevas » permettant de décomposer les éléments qui composent un modèle d’affaire. Les deux principaux sont le « Business Model Canvas » et le « Lean Canvas ». On peut les résumer en cinq questions principales (cf. Figure ci-dessous) :
- Qui sont les clients ? Quel est le marché que l’on cherche à adresser ?
- Quel est le problème ? Y a-t-il un besoin conscient de la part du client ?
- Quelle solution pouvons-nous proposer ? Quelle expérience utilisateur permet d’amener cette solution ?
- Quelles ressources sont nécessaires à la mise en œuvre de la solution ? Quelles données, quels algorithmes, quelles compétences ?
- Comment le problème du client et notre solution vont-ils se rencontrer ? Quelle sera la valeur retirée par chacun ?

chacune est nécessaire pour faire tenir la construction.
Pour une version plus exhaustive, on recommande fortement la lecture de La discipline entrepreneuriale qui présente en détail les 24 étapes de la construction du modèle d’affaire.
La compétence Business Model demande des connaissances de marketing (pour bien comprendre le marché et son fonctionnement, pour établir le prix, le processus de vente), de stratégie (pour établir la vision du produit) et une bonne compréhension de la démarche Lean Startup. Les compétences de growth marketing (modélisation du cycle de vie utilisateur, du moteur de croissance, tests d’hypothèses business) peuvent également être rattachées à cette catégorie de compétence.
Equilibrer les compétences
Après avoir décrit les 12 compétences techniques nécessaires à la valorisation des données, il reste à préciser comment celles-ci doivent être distribuées dans l’équipe. Il s’agit de résoudre une double problématique :
- Le spectre des 12 compétences nécessaires doit être globalement couvert, et certains membres de l’équipe doivent disposer d’un niveau d’expertise élevé dans leur domaine.
- Chaque compétence doit être « portée » par plusieurs équipiers avertis afin d’impacter l’ensemble de l’équipe et de favoriser la communication. En effet, il ne suffit pas d’avoir un expert dans l’équipe pour que celle-ci soit performante ; les autres équipiers doivent avoir une compréhension minimale dans chaque domaine pour se comprendre les uns les autres et pour prendre en compte les différentes facettes d’une problématique.
« Chacun a ses “majeures”, mais tout le monde doit pouvoir faire tout le job. »
On a besoin de compétences « hybridées tech + métier ».
Les compétences ne sont pas marquées ; chacun a « une majeure et plusieurs mineures ».
La Figure ci-dessous illustre ce que pourrait être une répartition « idéale » des compétences au sein d’une équipe :
- Chacun est expert dans une ou deux compétences.
- Chaque compétence est « portée » par un expert et plusieurs connaisseurs de niveau intermédiaire.
- Deux personnes dans l’équipe ont nécessairement une compétence en commun.
- Tout le monde a au moins des « notions » dans chaque compétence.

Bien sûr, cette répartition est théorique : On soulignait en introduction que les sept rôles ne correspondent pas nécessairement à sept postes différents. De plus, on ne trouvera probablement pas facilement tous ces profils. Mais le mode de représentation peut être utilisé pour évaluer les compétences d’une équipe : on repère ainsi facilement les compétences qui doivent être développées individuellement (expertise manquante) ou collectivement (expertise non partagée).
Ici se termine cet inventaires des compétences que l’on souhaite trouver dans une équipe produit data. Au delà des postes et des dénominations, c’est l’équilibre et le partage des compétences qu’il faut rechercher : une équipe où une compétence domine les autres aura tendance à avoir un jugement biaisé.
Pour éviter cela, posez-vous régulièrement la question. Y a-t-il des compétences absentes dans votre équipe produit ? Ou au contraire des compétences sur-représentées ? Comment ajustez-vous cet équilibre entre les différents aspects du produit ?
N’hésitez pas à réagir pour partager la façon dont vous gérez cet équilibre ; ou si vous voyez des compétences qui auraient mérité de figurer sur cette page. Enfin, pensez à me contacter si vous souhaitez approfondir cette problématique dans votre entreprise.
Vraiment intéressant ! Hâte de lire les prochains articles.
Merci pour le retour !
N’hésite pas à partager, ou à me dire sur quel sujet faire le prochain article…
A bientôt 😉